M9 · Evaluation¶
Goal: measure answer quality systematically — build a test set, score it with quality, agent, and custom evaluators, then run a batch
evaluate()that logs to the Foundry portal. You'll use:azure-ai-evaluation—RelevanceEvaluator,GroundednessEvaluator,IntentResolutionEvaluator,ToolCallAccuracyEvaluator, a custom callable, andevaluate(...).
So far you've built agents. Now you'll grade them. "It looked good when I tried it" doesn't scale — you need numbers you can track across prompt changes, model swaps, and releases. That's offline evaluation: run a fixed test set through your app and score each answer with evaluators.
The arc you'll build:
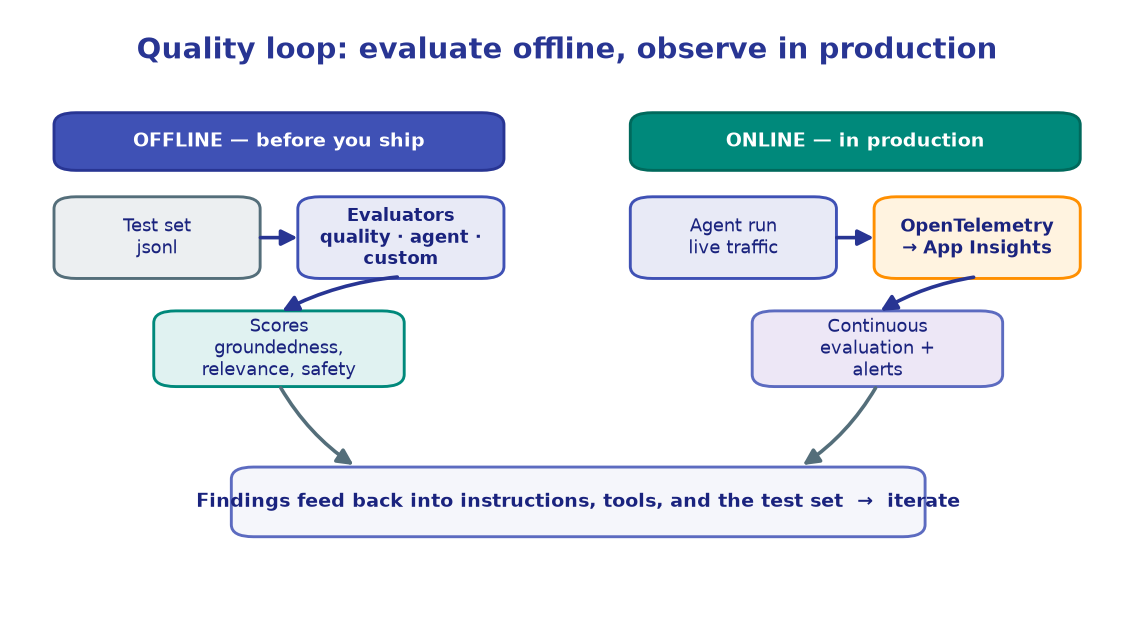
test dataset ──▶ quality evaluators (relevance, groundedness, coherence)
(jsonl) ──▶ agent evaluators (intent resolution, tool-call accuracy)
──▶ custom evaluator (your own scoring rule)
──▶ evaluate(...) batch ──▶ metrics + Foundry portal run
!!! note "One project, one grader model"
Most quality/agent evaluators are LLM-as-judge — they call a model to score
each answer. The reference derives a separate admin project from a hashed
subscription suffix; we just reuse this project's CHAT_MODEL as the judge. If
your .env isn't ready, do the Setup first.
1. Configure¶
Same .env as every lab. Evaluators that act as LLM-judges need the OpenAI-style
account endpoint (not the /api/projects/... path), so we derive it from
PROJECT_ENDPOINT — no extra variable to set.
import os, json
from pathlib import Path
from dotenv import load_dotenv
load_dotenv() # reads .env from the repo root
PROJECT_ENDPOINT = os.environ["PROJECT_ENDPOINT"]
CHAT_MODEL = os.environ.get("CHAT_MODEL", "gpt-4.1-mini")
# The judge model lives on the account; the AOAI endpoint is the account root,
# i.e. PROJECT_ENDPOINT with the "/api/projects/<project>" suffix removed.
AOAI_ENDPOINT = PROJECT_ENDPOINT.split("/api/projects/")[0] + "/"
print("Project :", PROJECT_ENDPOINT)
print("AOAI :", AOAI_ENDPOINT)
print("Judge :", CHAT_MODEL)
!!! note "Expected output"
Project : https://<account>.services.ai.azure.com/api/projects/<project> AOAI : https://<account>.services.ai.azure.com/ Judge : gpt-4.1-mini
The judge and the model under test happen to be the same deployment here; in
production you often grade a cheap model with a stronger judge.
2. The grader's model config¶
azure-ai-evaluation needs an AzureOpenAIModelConfiguration describing the judge
deployment, plus a DefaultAzureCredential for keyless Entra auth. The credential is
passed to each evaluator (not baked into the config) — this also sidesteps a known
Python 3.13 validation quirk in the 1.16.x SDK.
from azure.identity import DefaultAzureCredential
from azure.ai.evaluation import AzureOpenAIModelConfiguration
credential = DefaultAzureCredential()
model_config = AzureOpenAIModelConfiguration(
azure_endpoint=AOAI_ENDPOINT,
azure_deployment=CHAT_MODEL,
)
print("credential : ready")
print("model_config : ready ->", CHAT_MODEL)
!!! note "Expected output"
credential : ready model_config : ready -> gpt-4.1-mini
!!! warning "API is evolving"
Evaluator constructors and result keys shift between azure-ai-evaluation minor
versions. This lab is written for 1.16.x (pinned in pyproject.toml). If a
field name differs, check the version you installed.
3. A small test dataset¶
Evaluation starts with data: rows of query → response, plus the context the
answer should be grounded in and a ground_truth to compare against. The reference
captures these from a live agent thread; we hand-write four rows so the lab is
self-contained — and we make row 3 deliberately wrong so the scores have something
to catch.
records = [
{"query": "What does DefaultAzureCredential do in a Foundry app?",
"context": "DefaultAzureCredential tries credential sources in order (environment, "
"managed identity, az login) and uses the first that works — no secrets in code.",
"response": "It authenticates by trying several sources in sequence — environment "
"variables, managed identity, then your az login session — and uses the first "
"that succeeds, so you never hard-code secrets.",
"ground_truth": "Authenticates via a chain of sources (env, managed identity, az login); "
"requires no secrets in code."},
{"query": "How does agent versioning work in Foundry?",
"context": "An agent is stored under a stable name. create_version stores a new version "
"whenever the definition changes; callers reference the name.",
"response": "Each agent has a stable name, and create_version stores a new numbered version "
"whenever the definition changes. Callers reference the agent by name, so they "
"keep working as you publish new versions.",
"ground_truth": "Agents are stored by name; create_version makes a new version on each "
"change; callers reference by name."},
{"query": "What embedding size does text-embedding-3-large return?",
"context": "text-embedding-3-large returns 3072-dimensional vectors.",
"response": "The text-embedding-3-large model returns 1536-dimensional vectors by default.",
"ground_truth": "text-embedding-3-large returns 3072-dimensional vectors."},
{"query": "What is the Responses API used for?",
"context": "The Responses API is the modern stateful surface that powers agents and tools; "
"a minimal call takes a model and an input and returns output_text.",
"response": "It's Foundry's modern, stateful interface that powers agents and tools. A "
"minimal call passes a model and an input, and the reply is in output_text.",
"ground_truth": "Modern stateful API that powers agents and tools; minimal call takes "
"model + input, returns output_text."},
]
DATA_PATH = Path("eval_test_data.jsonl")
with DATA_PATH.open("w", encoding="utf-8") as fh:
for r in records:
fh.write(json.dumps(r) + "\n")
print(f"Wrote {len(records)} rows -> {DATA_PATH}")
print("Row 3 is intentionally wrong (1536 vs 3072) — watch groundedness flag it.")
!!! note "Expected output"
Wrote 4 rows -> eval_test_data.jsonl Row 3 is intentionally wrong (1536 vs 3072) — watch groundedness flag it.
A .jsonl file (one JSON object per line) is the format evaluate() consumes in
section 7. Real datasets have dozens to hundreds of rows; the shape is identical.
4. Quality evaluators¶
The bread-and-butter scores. Each is an LLM-as-judge returning a 1–5 score (plus a pass/fail against a threshold). We spot-check three on single rows:
- Relevance — does the answer address the question? (needs
query,response) - Groundedness — is it supported by the
context? (needsquery,response,context) - Coherence — is it logically structured? (needs
query,response)
from azure.ai.evaluation import (
RelevanceEvaluator, GroundednessEvaluator, CoherenceEvaluator,
)
relevance_eval = RelevanceEvaluator(model_config=model_config, credential=credential)
groundedness_eval = GroundednessEvaluator(model_config=model_config, credential=credential)
coherence_eval = CoherenceEvaluator(model_config=model_config, credential=credential)
good = records[0] # solid answer
bad = records[2] # the deliberately-wrong embedding row
print("GOOD row")
print(" relevance :", relevance_eval(query=good["query"], response=good["response"]))
print(" groundedness :", groundedness_eval(query=good["query"], response=good["response"], context=good["context"]))
print("\nBAD row (wrong dimension)")
print(" groundedness :", groundedness_eval(query=bad["query"], response=bad["response"], context=bad["context"]))
!!! note "Expected output" ``` GOOD row relevance : {'relevance': 5.0, 'relevance_result': 'pass', 'relevance_threshold': 3} groundedness : {'groundedness': 5.0, 'groundedness_result': 'pass', 'groundedness_threshold': 3}
BAD row (wrong dimension)
groundedness : {'groundedness': 2.0, 'groundedness_result': 'fail', 'groundedness_threshold': 3}
```
Exact scores vary, but the **contrast** is the point: the grounded answer scores high,
the contradicted one (1536 vs the context's 3072) gets flagged `fail`. That's the signal
you couldn't see by eyeballing.5. Agent-specific evaluators¶
Quality scores judge the answer. Agent evaluators judge the behaviour — did it understand intent and call the right tools? These also use the judge model:
- IntentResolutionEvaluator — did the agent grasp what the user wanted?
- TaskAdherenceEvaluator — did it follow its instructions?
- ToolCallAccuracyEvaluator — did it call the right tool with the right args?
We feed a captured turn directly. (For live agent threads, the SDK ships
AIAgentConverter to turn thread_id/run_id into this shape — see the note.)
from azure.ai.evaluation import (
IntentResolutionEvaluator, TaskAdherenceEvaluator, ToolCallAccuracyEvaluator,
)
intent_eval = IntentResolutionEvaluator(model_config=model_config, credential=credential)
adherence_eval = TaskAdherenceEvaluator(model_config=model_config, credential=credential)
toolcall_eval = ToolCallAccuracyEvaluator(model_config=model_config, credential=credential)
# A captured agent turn: user query, the tool the agent chose, and its final answer.
query = "How many dimensions does text-embedding-3-large output?"
response = "It returns 3072-dimensional vectors. [kb:embeddings]"
tool_calls = [{
"type": "tool_call", "tool_call_id": "call_1", "name": "kb_search",
"arguments": {"query": "text-embedding-3-large dimensions"},
}]
tool_definitions = [{
"name": "kb_search", "description": "Search the knowledge base for a query.",
"parameters": {"type": "object",
"properties": {"query": {"type": "string"}}, "required": ["query"]},
}]
print("intent resolution :", intent_eval(query=query, response=response))
print("task adherence :", adherence_eval(query=query, response=response))
print("tool-call accuracy:", toolcall_eval(query=query, tool_calls=tool_calls, tool_definitions=tool_definitions))
!!! note "Expected output"
intent resolution : {'intent_resolution': 5.0, 'intent_resolution_result': 'pass', ...} task adherence : {'task_adherence': 4.0, 'task_adherence_result': 'pass', ...} tool-call accuracy: {'tool_call_accuracy': 5.0, 'tool_call_accuracy_result': 'pass', ...}
!!! tip "Capturing real agent threads"
Instead of hand-building tool_calls, point AIAgentConverter(project_client).convert( thread_id, run_id) at a real run from M3
to produce eval-ready rows. The converter's exact signature is evolving across SDK
releases — pin azure-ai-evaluation and check its version if a field differs.
6. A custom evaluator¶
Built-ins won't cover every rule your domain cares about. A custom evaluator is just a
callable returning a score dict — no LLM required. Here we enforce a contract: the
answer must cover the key terms from its ground_truth. Simple, deterministic, cheap.
class KeyTermCoverageEvaluator:
"""Score = fraction of ground_truth key terms that appear in the response."""
def __init__(self, min_len=4, threshold=0.5):
self.min_len = min_len # ignore short/stop-ish words
self.threshold = threshold # pass if coverage >= this
def __call__(self, *, response: str, ground_truth: str, **kwargs) -> dict:
terms = {w.lower().strip(".,;:()") for w in ground_truth.split() if len(w) >= self.min_len}
hay = response.lower()
hits = {t for t in terms if t in hay}
coverage = round(len(hits) / len(terms), 2) if terms else 0.0
return {
"key_term_coverage": coverage,
"key_term_pass": coverage >= self.threshold,
}
cov = KeyTermCoverageEvaluator()
print("good row:", cov(response=records[0]["response"], ground_truth=records[0]["ground_truth"]))
print("bad row:", cov(response=records[2]["response"], ground_truth=records[2]["ground_truth"]))
!!! note "Expected output"
good row: {'key_term_coverage': 0.8, 'key_term_pass': True} bad row: {'key_term_coverage': 0.43, 'key_term_pass': False}
Any object with a __call__ returning a {metric: value} dict is a valid evaluator —
evaluate() treats your class exactly like the built-ins. Use this for business rules:
citation format, banned phrases, length bounds, schema checks.
7. Batch evaluate → metrics + portal¶
Spot-checks are for debugging; evaluate() is the real run. It applies all evaluators
across every row of the .jsonl, aggregates metrics, and — when you pass
azure_ai_project — uploads the run to the Foundry portal and returns a studio_url.
column_mapping tells each evaluator which dataset columns to read.
from azure.ai.evaluation import evaluate
results = evaluate(
data=str(DATA_PATH),
evaluators={
"relevance": relevance_eval,
"groundedness": groundedness_eval,
"coherence": coherence_eval,
"key_term": KeyTermCoverageEvaluator(),
},
evaluator_config={
"relevance": {"column_mapping": {"query": "${data.query}", "response": "${data.response}"}},
"groundedness": {"column_mapping": {"query": "${data.query}", "response": "${data.response}",
"context": "${data.context}"}},
"coherence": {"column_mapping": {"query": "${data.query}", "response": "${data.response}"}},
"key_term": {"column_mapping": {"response": "${data.response}",
"ground_truth": "${data.ground_truth}"}},
},
azure_ai_project=PROJECT_ENDPOINT, # uploads the run + returns a studio_url
output_path="eval_results.jsonl",
)
print("Aggregate metrics:")
for k, v in results.get("metrics", {}).items():
print(f" {k:<32} {v}")
print("\nPortal:", results.get("studio_url", "(no studio_url — check azure_ai_project)"))
!!! note "Expected output" ``` Aggregate metrics: relevance.relevance 4.75 groundedness.groundedness 4.25 coherence.coherence 4.50 key_term.key_term_coverage 0.71 key_term.key_term_pass 0.75
Portal: https://ai.azure.com/.../evaluation/<run-id>
```
The means hover high because three of four rows are solid; the wrong embedding row drags
`groundedness` and `key_term` down — exactly the regression signal you want. Open the
`studio_url` to see per-row scores, judge reasoning, and a trend line across runs.!!! tip "This is the foundation for the next lab" Offline evaluation runs before you ship. In M10 you'll wire the same evaluators to run continuously on live production traffic — the other half of the quality loop in the diagram above.
🧪 Your turn¶
- Break a good row. Edit row 1's
responseto contradict itscontext, re-write the.jsonl, and re-run section 7 — watchgroundednessdrop and the row flip tofail. - Add Fluency + Similarity. Import
FluencyEvaluatorandSimilarityEvaluator, add them to theevaluators=dict (similarity needsground_truthin itscolumn_mapping), and compare the new columns. - Tighten your custom rule. Raise
KeyTermCoverageEvaluator(threshold=0.8)and re-run — more rows fail. This is how you turn a soft expectation into an enforceable gate.
✅ You built a test set, scored it with quality, agent, and custom evaluators, and ran a
batch evaluate() that logs to the Foundry portal. Next: watch those same signals on live
traffic with tracing and continuous evaluation.
→ M10 · Observability & Tracing